Speakeasy vs Open Source: OpenAPI Python Client Generation
Many of our users have switched from OpenAPI Generator to Speakeasy for their Python SDKs.
Open-source OpenAPI Generators are great for experimentation, but don't offer the reliability, performance, and intuitive developer experience required for critical applications. As an alternative, Speakeasy generates idiomatic client SDKs that meet the bar for enterprise use.
In this post, we'll focus on Python, but Speakeasy can also generate SDKs in Go, Typescript, Java, Ruby, PHP and more.
View More Comparisons
We'll generate a Python SDK using Speakeasy, then compare it to SDKs generated by OpenAPI Generator; demonstrating how Speakeasy improves upon the open-source generators by offering:
- Exceptional code readability
- Improved models
- Fewer dependencies
- Managed CI/CD
Installing SDK generators
To start our comparison, we installed both generators on a local machine running macOS.
Our experience installing the OpenAPI Generator CLI
To install OpenAPI Generator, we followed the steps in the OpenAPI Generator CLI installation (opens in a new tab) documentation.
As recommended in the documentation, we started by installing the NPM package, openapi-generator-cli. The installation seemed to work without any errors, but running this node package generated Java errors.
Searching the OpenAPI Generator issues on GitHub led us to believe that the root problem was an incompatible Java version. After installing and unsuccessfully fiddling with jenv, which enables switching between multiple Java versions, we consulted the OpenAPI documentation again.
The next recommended installation method for OpenAPI Generator for macOS is via Homebrew. Inspecting the Homebrew formula (opens in a new tab) for openapi-generator, we saw that openapi-generator depends on OpenJDK v11, which would explain why we couldn't get the NPM installation to work earlier.
We ran the Homebrew installer, which installed openjdk@11 along with a slew of dependencies:
brew install openapi-generator
How to install the Speakeasy CLI
To install the Speakeasy CLI, we'll follow the steps in the Speakeasy Getting Started guide.
In the terminal, run:
brew install speakeasy-api/homebrew-tap/speakeasy
Next, authenticate with Speakeasy by running the following:
speakeasy auth login
This installs the Speakeasy CLI as a single binary without any dependencies.
Downloading the Swagger Petstore specification
Before we run our generators, we'll need an OpenAPI specification to generate a Python SDK for. The standard specification for testing OpenAPI SDK generators and Swagger UI generators is the Swagger Petstore (opens in a new tab).
We'll download the YAML specification at https://petstore3.swagger.io/api/v3/openapi.yaml (opens in a new tab) to our working directory and name it petstore.yaml:
curl https://petstore3.swagger.io/api/v3/openapi.yaml --output petstore.yaml
Validating the spec
Both the OpenAPI Generator and Speakeasy CLI can validate an OpenAPI spec. We'll run both and compare the output.
Validation using OpenAPI Generator
To validate petstore.yaml using OpenAPI Generator, run the following in the terminal:
openapi-generator validate -i petstore.yaml
The OpenAPI Generator returns two warnings:
Warnings: - Unused model: Address - Unused model: Customer[info] Spec has 2 recommendation(s).
Validation using Speakeasy
We'll validate the spec with Speakeasy by running the following in the terminal:
speakeasy validate openapi -s petstore.yaml
The Speakeasy validator returns ten warnings, seven hints that some methods don't specify any return values and three unused components. Each warning includes a detailed JSON-formatted error with line numbers.
Since both validators validated the spec with only warnings, we can assume that both will generate SDKs without issues.
Generating an SDK
Now that we know our OpenAPI spec is valid, we can start generating SDKs. We'll start with OpenAPI Generator again, then move on to Speakeasy.
We'll generate each SDK in a unique subdirectory of a new directory called sdks.
OpenAPI Generate
The OpenAPI Generator includes four different Python SDK generators:
- python
- python-legacy
- python-nextgen
- python-prior
In this post, we'll focus on two stable Python SDK generators: python (opens in a new tab), and python-nextgen.
Usage is the same for both, but we'll specify a unique output director, generator name, and project name for each generator.
We'll generate an SDK for each by running the following in the terminal:
# Generate Petstore SDK using python generatoropenapi-generator generate \ --input-spec petstore.yaml \ --generator-name python \ --output ./sdks/petstore-sdk-python \ --additional-properties=packageName=petstore_sdk,projectName=petstore-sdk-python# Generate Petstore SDK using python-nextgen generatoropenapi-generator generate \ --input-spec petstore.yaml \ --generator-name python-nextgen \ --output ./sdks/petstore-sdk-python-nextgen \ --additional-properties=packageName=petstore_sdk,projectName=petstore-sdk-python-nextgen
Both commands will output a list of files generated. In our testing, the python-nextgen generator was significantly faster to complete and its list of files was shorter. We'll look into how and why these two generators differ shortly.
Speakeasy generate
Next, we'll generate an SDK using the Speakeasy CLI.
# Generate Petstore SDK using Speakeasy python generatorspeakeasy generate sdk \ --schema petstore.yaml \ --lang python \ --out ./sdks/petstore-sdk-python-speakeasy/
SDK code compared: Package structure
We now have three different Python SDKs for the Petstore API:
./sdks/petstore-sdk-python/, which we'll call the Python SDK../sdks/petstore-sdk-python-nextgen/, which we'll call the Python Nextgen SDK../sdks/petstore-sdk-python-speakeasy/, which we'll call the Speakeasy SDK.
We'll start our comparison by looking at the structure of each generated SDK.
To count the lines of code in each SDK, we'll run cloc for each:
cloc ./sdks/petstore-sdk-pythoncloc ./sdks/petstore-sdk-python-nextgencloc ./sdks/petstore-sdk-python-speakeasy
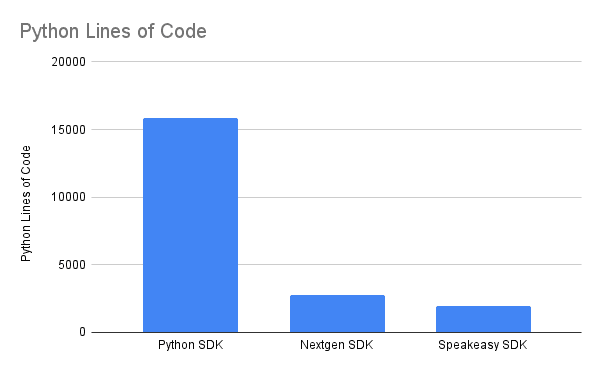
Immediately, we see that the Speakeasy SDK is significantly smaller in terms of lines of code.
Let's look at why the Python SDK has so many files and lines of code. The Python SDK includes 21 stub files, which account for 5,588 lines of code. On inspection, we found that these stub files, which have the extension .pyi, are identical to their Python counterparts.
We consulted the generator's source (opens in a new tab) and found this explanation:
This stub file exists to allow pycharm to read and use typing.overload decorators for it to see that dict_instance["someProp"] is of type SomeClass.properties.someProp
Another factor contributing to the number of files in the Python SDK is how this SDK splits each path into a separate directory, with each HTTP method in a separate Python file (and corresponding stub file). For example, in the Python SDK, the find_pet_by_status path is a directory, with a Python file for the get method, while in Python Nextgen and Speakeasy, each model's API paths and methods are grouped together per model.
Because of the simpler package structure, we found it easier to navigate, search, and read the Python Nextgen SDK and Speakeasy SDK source.
Models, data containers, and typing
All three SDKs use unique typing annotations in their models.
In the Python SDK, models inherit from a custom DictSchema class that performs basic validation and provides methods for serializing and deserializing objects. The objects created by these models are immutable. The code for the Python SDK's models is verbose and complex, which makes it hard to read.
The Python Nextgen SDK and Speakeasy SDK both use less complex, more readable data structures for models.
The Python Nextgen SDK's models inherit from the Pydantic BaseModel class. Pydantic (opens in a new tab) validates data at runtime and provides clear error messages when data is invalid.
For example, creating a Pet object with the name field set to an integer value will generate a type validation error:
# Python Nextgen SDKimport petstore_sdkpet = petstore_sdk.Pet(id=1, name="Archie", photoUrls=[])pet2 = petstore_sdk.Pet(id=2, name=2, photoUrls=[])# > pydantic.error_wrappers.ValidationError: 1 validation error for Pet# > name# > str type expected (type=type_error.str)
The Speakeasy SDK's models are decorated with @dataclasses.dataclass and @dataclass_json. Data Classes (opens in a new tab) automatically add special methods such as __init__ and __repr__ to Python classes, which reduces boilerplate and improves readability.
Fields in Speakeasy's models are type-annotated and contain metadata to specify how each field should be serialized or deserialized in different formats.
While Speakeasy does not enforce types at runtime, type hints provide a friendly developer experience when using an IDE.
To illustrate the readability of generated models, here's the Pet model generated by Speakeasy:
# Speakeasy SDK Pet Model@dataclass_json(undefined=Undefined.EXCLUDE)@dataclasses.dataclassclass Pet: r"""Create a new pet in the store""" name: str = dataclasses.field( metadata={ "dataclasses_json": {"letter_case": utils.get_field_name("name")}, "form": {"field_name": "name"}, } ) photo_urls: list[str] = dataclasses.field( metadata={ "dataclasses_json": {"letter_case": utils.get_field_name("photoUrls")}, "form": {"field_name": "photoUrls"}, } ) category: Optional[shared_category.Category] = dataclasses.field( default=None, metadata={ "dataclasses_json": { "letter_case": utils.get_field_name("category"), "exclude": lambda f: f is None, }, "form": {"field_name": "category", "json": True}, }, ) id: Optional[int] = dataclasses.field( default=None, metadata={ "dataclasses_json": { "letter_case": utils.get_field_name("id"), "exclude": lambda f: f is None, }, "form": {"field_name": "id"}, }, ) status: Optional[PetStatusEnum] = dataclasses.field( default=None, metadata={ "dataclasses_json": { "letter_case": utils.get_field_name("status"), "exclude": lambda f: f is None, }, "form": {"field_name": "status"}, }, ) r"""pet status in the store""" tags: Optional[list[shared_tag.Tag]] = dataclasses.field( default=None, metadata={ "dataclasses_json": { "letter_case": utils.get_field_name("tags"), "exclude": lambda f: f is None, }, "form": {"field_name": "tags", "json": True}, }, )
The way Speakeasy provides a clean interface for enums contrasts with the string-based specification and validation generated by Python Nextgen.
# Python Nextgen SDK Pet Model snippetclass Pet(BaseModel): # ... @validator('status') def status_validate_enum(cls, v): if v is None: return v if v not in ('available', 'pending', 'sold'): raise ValueError("must be one of enum values ('available', 'pending', 'sold')") return v
The Speakeasy enum in this case is much more readable:
# Speakeasy SDK Status Enumclass PetStatusEnum(str, Enum): r"""pet status in the store""" AVAILABLE = "available" PENDING = "pending" SOLD = "sold"
SDK Dependencies
Speakeasy generates SDKs with fewer dependencies, to ensure that our SDKs support as many environments as possible. We'll compare the notable differences in dependencies between the generated SDKs.
HTTP client library
The two OpenAPI Generator SDKs both use urllib3 in their HTTP clients, while the Speakeasy SDK uses the Requests (opens in a new tab) library.
The Requests library leads to less verbose code, which makes the Speakeasy SDK exceptionally readable:
def add_pet_json(self, request: shared.Pet, security: operations.AddPetJSONSecurity) -> operations.AddPetJSONResponse: r"""Add a new pet to the store Add a new pet to the store """ base_url = self._server_url url = base_url.removesuffix('/') + '/pet' headers = {} req_content_type, data, form = utils.serialize_request_body(request, "request", 'json') if req_content_type not in ('multipart/form-data', 'multipart/mixed'): headers['content-type'] = req_content_type if data is None and form is None: raise Exception('request body is required') client = utils.configure_security_client(self._client, security) http_res = client.request('POST', url, data=data, files=form, headers=headers) content_type = http_res.headers.get('Content-Type') res = operations.AddPetJSONResponse(status_code=http_res.status_code, content_type=content_type, raw_response=http_res) if http_res.status_code == 200: if utils.match_content_type(content_type, 'application/json'): out = utils.unmarshal_json(http_res.text, Optional[shared.Pet]) res.pet = out if utils.match_content_type(content_type, 'application/xml'): res.body = http_res.content elif http_res.status_code == 405: pass return res
Typing library
The Speakeasy SDK uses dataclasses decorators from the Python standard library, which is more performant than third-party typing libraries, leads to better readability, and does not add additional dependencies to the generated SDK.
Supported Python versions
When we did our comparison, the Speakeasy SDK required at least Python 3.9, which is supported until October 2025, while the OpenAPI-generated SDKs both require the soon-to-be deprecated Python 3.7.
Retries
The SDK generated by Speakeasy can automatically retry failed network requests, or retry requests based on specific error responses.
This provides a straightforward developer experience for error handling.
To enable this feature, we need to use the Speakeasy x-speakeasy-retries extension to the OpenAPI spec. We'll update the OpenAPI spec to add retries to the addPet operation as a test.
Edit petstore.yaml and add the following to the addPet operation:
x-speakeasy-retries: strategy: backoff backoff: initialInterval: 500 # 500 milliseconds maxInterval: 60000 # 60 seconds maxElapsedTime: 3600000 # 5 minutes exponent: 1.5
Add this snippet to the operation:
#...paths: /pet: # ... post: #... operationId: addPet x-speakeasy-retries: strategy: backoff backoff: initialInterval: 500 # 500 milliseconds maxInterval: 60000 # 60 seconds maxElapsedTime: 3600000 # 5 minutes exponent: 1.5
Now we'll rerun the Speakeasy generator to enable retries for failed network requests when creating a new pet. It is also possible to enable retries for the SDK as a whole by adding global x-speakeasy-retries at the root of the OpenAPI spec.
Generated documentation
Each SDK generator creates a docs directory with documentation and usage examples.
We found that the usage examples in the Python SDK and Speakeasy SDK work flawlessly, while the examples generated for the Nextgen SDK don't always include required fields when instantiating objects.
The Python SDK's documentation is especially thorough regarding models, with a table of fields and their types for each model.
The Speakeasy SDK's documentation is focused on usage, with a usage example for each operation for each model.
The Speakeasy generator also generates appropriate example strings, based on a field's format in the OpenAPI spec.
For example, if we add format: uri to the item spec for a pet's photo URLs, we can compare what each generator creates for this field's usage documentation.
The SDK generated by Speakeasy includes a helpful example of this field that lists multiple random URLs:
# Speakeasy SDK Usage Examplepet = shared.Pet( # ... photo_urls=[ 'https://salty-stag.name', 'https://moral-star.info', 'https://present-giggle.info', ])
The Python SDK's documentation uses a single random string in its example:
# Python SDK Usage Examplepet = Pet( # ... photo_urls=[ "photo_urls_example" ])
The Nextgen SDK doesn't include this specific field in its examples.
Automation
This comparison focuses on the installation and usage of command line generators, but the Speakeasy generator can also run as part of a CI workflow, for instance as a GitHub Action (opens in a new tab), to make sure your SDK is always up to date when your API spec changes.
Summary
In summary, OSS tooling can be a great way to experiment, but if you're working on a production use case, Speakeasy Python SDK generator can help ensure that you create reliable and performant Python SDKs.
The Speakeasy Python SDK generator uses data classes, which provide good runtime performance and exceptional readability. Automatic retries for network issues makes error handling straightforward. Speakeasy's generated documentation includes a working usage example for each operation. Unlike other Python SDK generators, Speakeasy can publish your generated SDK to PyPI and run as part of your CI workflows.